

Introduction
Large Language Models (LLMs) like OpenAI’s GPT series have revolutionized AI’s ability to perform tasks with advanced reasoning capabilities. However, they often lack one crucial element that humans naturally possess— the ability to think before responding. While techniques like Chain-of-Thought (CoT) prompting have been introduced, these have been limited to specific tasks, such as mathematical problem-solving.
Researchers from Meta FAIR, UC Berkeley, and NYU have now developed a groundbreaking technique called Thought Preference Optimization (TPO), allowing LLMs to optimize their thought processes and improve performance in a wider range of tasks without needing additional human-labeled data.
Why Thought Processes Matter in AI
Humans often engage in internal deliberation before responding to complex queries, giving them the ability to refine their responses. For LLMs, this internal thinking is equally important, especially for challenging tasks that require deeper reasoning. Previously, models have struggled to incorporate this “thinking” phase.
The concept of Thought Preference Optimization (TPO) builds on this. It allows LLMs to generate internal thought processes before providing a final response. This method aims to improve not only logical tasks like problem-solving but also tasks that require creativity, general understanding, or planning, such as creative writing and instruction-following.
What is Thought Preference Optimization (TPO)?
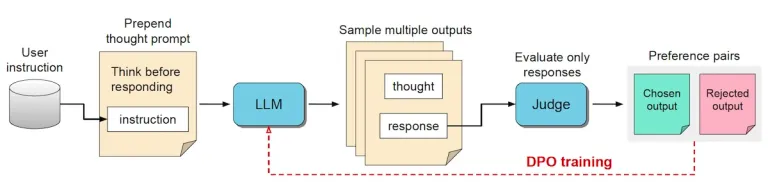
Thought Preference Optimization (TPO) is a new training method developed to optimize how LLMs “think” before responding. The idea is simple but powerful: train the model to separate its thinking process from the final response. During training, the LLM generates an internal “thought” component, which remains hidden from the user, followed by a response component.
To refine the model’s internal thinking, the researchers use Reinforcement Learning from AI Feedback (RLAIF). This technique evaluates the final response without evaluating the internal thought process. A “judge” model is trained to provide feedback on the response quality, and the LLM adjusts its internal process based on this feedback.
- No human-labeled data required: TPO eliminates the need for manually labeled datasets of human thought processes.
- Focus on final output: Instead of explicitly guiding thoughts, TPO optimizes the response quality, indirectly improving the LLM’s internal reasoning.
Evaluating the Performance of Thinking LLMs
To test the effectiveness of TPO, the researchers used the Llama-3-8B-Instruct model as the base, and evaluated it using benchmarks like AlpacaEval and Arena-Hard. These benchmarks test the LLM’s ability to follow complex instructions.
The results were promising:
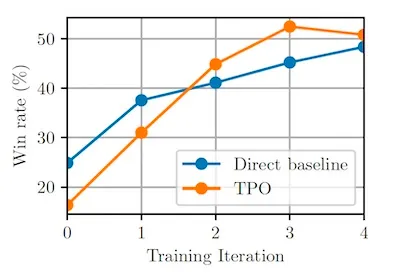
- Initially, prompting LLMs to think before responding led to a performance drop. However, after several iterations of TPO training, the models began to outperform their non-thinking counterparts.
- The Thinking LLM excelled in both traditional reasoning tasks and creative tasks, like writing poetry. This shows that the ability to think improves more than just logical reasoning—it also enhances creative and general knowledge-based tasks.
In benchmarks, the Thinking LLM demonstrated a higher win rate compared to baseline models, proving that TPO enhances performance across a variety of tasks, not just those typically associated with reasoning.
Future of Thought-Optimized LLMs
The development of Thought Preference Optimization opens a new frontier for LLMs, allowing them to independently learn how to think before responding. This method can be applied across various tasks, offering more robust solutions for everything from simple instructions to complex problem-solving.
The researchers believe that this new method could eventually lead to even more advanced thinking LLMs capable of handling a wider range of general instructions, expanding beyond specialized tasks like math or logical reasoning. As AI continues to develop, the ability to “think” like a human could become a defining feature of future LLMs.
Conclusion
Thought Preference Optimization (TPO) represents a major advancement in LLM training. By teaching LLMs to think internally before responding, this method improves their ability to follow complex instructions and complete creative tasks. As AI models continue to evolve, TPO is poised to unlock new levels of performance across a broad spectrum of applications.
Other Posts :
Gemini 1.5 : https://maticsacademy.com/gemini-1-5-google-ai-language-models/
ChatGpt Voice API : https://maticsacademy.com/chatgpt-voice-api-financial-scams/
How ChatGpt Search is Revolutionizing the Ai Powered Research : https://maticsacademy.com/how-chatgpt-search-is-revolutionizing-ai-powered-search/
Related Posts :
Meta’s FAIR Research : https://ai.meta.com/research/
OpenAI’s Advancements : https://openai.com/research/







